Only recently did i manage to read the November 2014 report published by the Institute of Fiscal Studies (but joint with the Institute of Education and NFER, funded by Nuffield) on the Costs and Benefits of Different Initial Teacher Training Routes. It is an interesting read; it would go too far to comment on all of the content, but it was striking that different media outlets chose different ‘slants’ on the report.
IFS had quite an extensive press release highlighting several aspects, while the NFER chose three of the findings. The report is an interim report from a Nuffield project (I noticed Nuffield funds the IFS for more ‘public spending’ projects).
It is fascinating to see how outsiders reported or blogged about the results. John Howson seems to emphasize the monetarization and quantification of ITT routes. I agree with him that this could turn into an issue: it’s shouldn’t solely be about numbers. However, for public justification of expenses in principle it is important to explain how public money is spent. The Public Finance website had quite a factual report, and among other points, noted how the issies around student loans and repayments. The University and College Union (UCU) also picked up this point but, in my opinion rightly so, asks attention to the longterm effects of the changing ITT landscape, and the hidden costs involved. They emphasize the threat to university education departments caused by reducing the direct allocation of training places to universities. A school-based teacher training provision prefers to highlight (and not suprisingly agree with) the result that a higher percentage of school-based ITT responded that the benefits of the route outweigh the costs. In a more extensive piece in Academies Week many of all these findings come together in one piece. It also mentions the ‘benefits’ of ITT routes. As this also got a mention in some tweets at the time, I’d thought I’d look into how this benefit (and costs of course) was determined in the report.
Chapter 4 of the report breaks down this topic. It first addresses the ‘central costs’ in 4.1, in which scholarships, bursaries, tuition fees and maintenance loans, maintenance grants, NCTL grants to schools, and NCTL contracts are taken into account. The key table is below. I was wondering who the recipients of these costs were throughout the report. For example, a bursary will be received by a trainee, a tuiton fee loan paid (back) by students but going to HEI’s etc. etc.

After this the indirect costs for schools are caclulated in 4.2. Note that throughout the report focus is ‘Inner London’, but both primary and secondary education are looked at. This was done by, per term for primary and secondary education, looking at costs for mentoring, observations, lesson planning and other costs. This is where I feel the estimates become a bit vague. The estimates for the costs were obtained by asking respondents to report the time involved with the indirect costs associated with a specific trainee. This was combined with information on the pay category of the lead staff member involved, also representing the ‘opportunity costs of training’. The largest cost associated with ITT for primary schools is mentoring, with an average cost of around £39 per week. For secondary schools the highest was ‘observations’ and I was struck by the difference between routes: Teach First costs £29 per week, HEI-led £81 per week. I seriously wonder how this can be the case. It certainly explains the secondary schools differences in table 4.5 below.
 Section 4.3 then describes the benefits. I was particularly interested how the report would calculate (monetize) the benefits. Apparently it started with a simple question: respondents were asked to report the extent to which the specific trainee in their recent experience brought a number of benefits to their school/department. These benefits, and percentages ‘strongly agree’ or ‘agree’ are reported in tables 4.7 and 4.8.
Section 4.3 then describes the benefits. I was particularly interested how the report would calculate (monetize) the benefits. Apparently it started with a simple question: respondents were asked to report the extent to which the specific trainee in their recent experience brought a number of benefits to their school/department. These benefits, and percentages ‘strongly agree’ or ‘agree’ are reported in tables 4.7 and 4.8.

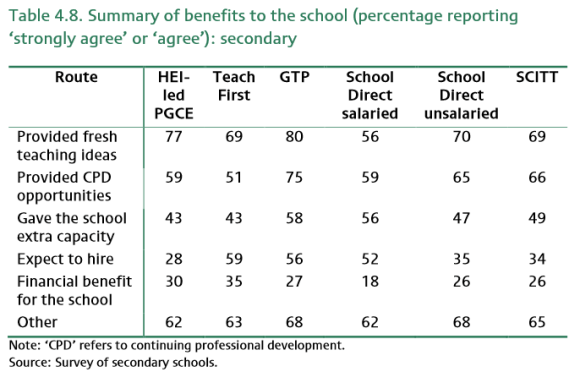 The monetary value was calculated by asking an additional question “whether the benefit for their school or department was greater than, equal to or less than the cost associated with the route, and whether this was to a ‘large’, ‘some’ or ‘small’ extent. Now, this seems somewhat subjective, maybe captured by the report’s use of the word ‘perception’.
The monetary value was calculated by asking an additional question “whether the benefit for their school or department was greater than, equal to or less than the cost associated with the route, and whether this was to a ‘large’, ‘some’ or ‘small’ extent. Now, this seems somewhat subjective, maybe captured by the report’s use of the word ‘perception’.

For primary, it is reported, whether it is reported that benefits outweigh the cost is related to specific benefits, especially whether the school expects to hire the trainee. This seems understandable, because you would want a large (time and money) investment not to leave the next year.
For secondary to groups of people were asked: secondary subject leaders (Departments) and secondary ITT coordinators.
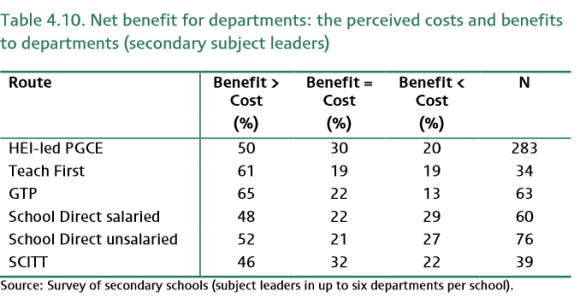

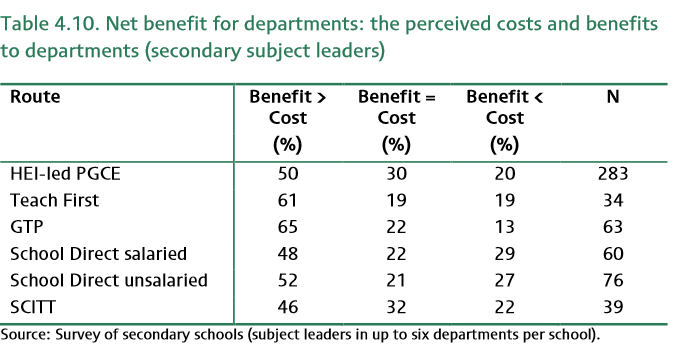
This is all quite informative, although interpretation is difficult. It’s the subsequent monetarization that made me scratch my head. This started with assuming that net benefit was a continous variable with the answers to the question whether the benefits were less, equal or larger and the extent, as underlying property. A next assumption then is that the benefit-cost ratio has a Gamma distribution. It is argued that ‘this is reasonable’ as it is flexible and because ‘it can approximate a large range of distributions depending on the parameters.’. I find this justification unconvincing. But the assumptions continue with the assumption that respondents’ interpretation of ‘large’, ‘some’ and ‘small’ extent is similar AND that the value for each is the same above and below benefits=costs. A final assumption concerns a margin of approximation (see p.49 and appendix D of the report). Then the gamma distribution was fit to the survey results, and then draws made from the optimal gamma distribution. The draws were averaged to provide average net benefit. For the three groups, primary, seocondary subject leaders and ITT coordinators the corresponding tables are 4.16, 4.17 and 4.18:


These tables seem to show what these assumptions do with the results. Take Teach First, the report mentions that, for ITT coordinators, the very high average net benefit is mainly caused by higher monetary costs as reported by the ITT coordinators, but also a higher estimated benefit-cost ratio. I thought the former was very strange as table 4.6 seemed to indicate that the costs were among the lowest. I find it difficult to understand what causes the difference between these observations. This is important to understand as high costs, combined with high benefit-cost ratio, imply more benefit. The calculation of the ratio also needs to be unpicked. I somehow feel that there are far too many assumptions here for such a conclusion, especially given the nature of the original questions. One could argue that it basically is a 7-point Likert scale with benefits to large extent less than costs, to, benefits to large extent more than the costs. With assumptions that these ‘steps’ are equal, Gamma distrubution assumptions, but also that it concerns the perception of benefits-costs ratio, seems problematic to me. Appendix D further explains the procedure and it seems that the first column is the average of the calculated benefit-cost ratios (those drawn from the Gamma distribution, I presume). It makes a big difference whether values are drawn to the right of the distribution or not. Now had I taken from table 4.11, for example, that benefits>cost percentage for HEI-led ITT was comparable to, for example Teach First. I have no idea why the benefit-cost ratio is lower. Overall, given all the assumptions I think the net benefits reported in terms of ‘monetarization’ are not really sound.
 Like so many people I’ve never really liked transcribing audio, for example from interviews or focus groups. It is time-consuming and boring. Of course, you can outsource this but that unfortunately costs money. So I thought: “how can I do this quicker with available services.”
Like so many people I’ve never really liked transcribing audio, for example from interviews or focus groups. It is time-consuming and boring. Of course, you can outsource this but that unfortunately costs money. So I thought: “how can I do this quicker with available services.”




















 t
t


