This Thursday March 21st, I attended the eighth “What The Research Says” session at the London Knowledge Lab on Big data and Learning Analytics.
The first presentation was by Jenzabar, a service provider from Boston, USA about predictive modelling of student performance. Main objectives of the project involves academic achievement and at-risk-students. The speaker talked about some developments through the years on predictive modelling, touching upon point-in-time assessments/surveys, lagging indicators and early warnings based on observations. The second presentation was about Arbor, an adaptive system. Apparently, they sport the first NoSQL database system, using tags to capture data. Other systems can connect to their API. The third presentation by Alexandra Poulovassilis was about several tracking tools, most concerned with the Migen project. She described the evolution of teacher tools for student progress within the system. She showed an, in my opinion, very interesting visualization of student progress, essentially a logfile. I recognized a lot of the difficulties with analyzing logfiles of student progress in my PhD. Good to see they’re working on a web-based version as well. The fourth presentation showed Maths-Whizz work. I was impressed by their dashboard and visualization. Less impressed by the actual maths content I saw in the sample. For example, why do I get 0 points if my third step in the equation in the figure?
After this I attended a more detailed session by Jenzabar. Very interesting to hear more about the Learning Analytics (or is it data mining? ;-)) process. Familiar terms like logistic regression were touched upon. It resembles some of the work I’m doing now, looking at models and seeing what recall, precision etc. are. As a system, Jenzabar looks great. Visiting their website I can read Jenzabar describes themselves as “Software, strategies, and services empowering higher ed institutions to meet administrative and academic needs.”. That explains a lot; as an educator I’m more interested in what actually happens in classrooms, rather than the admin surrounding them. Algorithms behind the system range from uni-variate models to multivariate, naive-Bayes and regression. They aim for at least 85-95% correct predictions.
I did not have much time to look at many other systems. The discussion at the end of the session primarily touched upon privacy and ethical aspects of big data. Like other topics there seems to be quite some polarization in this discussion. on the one hand you have the people (the USA seems to be pretty easy with data) who don’t seem to see anything non-ethical about collecting data from students. The other extreme is that you would have to ask permission about anything. I don’t recall that teachers who conduct pen-and-paper tests or check homework had to ask students whether they could make a judgment based on the data collected. I think the answer (again) is in the middle: we can and should use student data (I prefer the more qualitative data) but must use it sensibly. The day finished with someone suggesting we should look into ‘teaching analytics’. I agree, that’s why we’ve put this in a European bid.
The fourth session by Ainley reported on the Fibonacci project, integrating inquiry in mathematics and science education. It was good to hear that the word ‘utility’ that was used, did not refer to a utilitarian view of maths, i.c. that everything should have a clear purpose. I mention this as discussions about utility often tend to end in comments like ‘what’s the point of doing algebra’? Actually, I think that does have a purpose, amongst others ‘analytical thinking’ but I prefer steering clear from these types of pointless discussions. The best slide, I though, was a slide with science, statistics and mathematics in the columns and rows with a distinction in, for example, their purpose.
It formed a coherent picture of STEM. The two examples for integrative projects were ‘building a zoo’ which I didn’t like when it concerned the context of fences that had to be built. It’s the lack of creativity that often is in textbooks as well. the second project, on gliders, was more interesting but the mathematical component seemed to belong more in statistics used. I would loved to have seen a good mathematical example.
The fifth session by Hassler and Blair was about Open Educational Resources. The project, funded by JISC, acknowledged three freedoms: legal, technical and educational. It is a project that boasted a website with educational resources, free to use, keywords and with pdf creator. Although nicely implemented, to me, it seemed to be a bit ‘yet another portal’. The individual elements weren’t that novel either, with for example a book creator also in the Activemath project. The most interesting thing was the fact that the materials were aimed at ‘interactive teaching’.
The sixth and last session was a presentation by Kislenko from Estiona. She described how in Estonia a new curriculum was implemented for educating teachers in mathematics and natural sciences. It was an interesting story, although I was wondering how ‘new’ it was, as the title had the term ‘innovative’ in it.
Together with some networking these sessions made up an interesting and useful day in Cambridge.
The third session I attended was more a discussion and critique session, led by Monaghan and Mason, on the topic of ‘cultural affordances’. The basis was the work of Chiappini, who -in the ReMath project- used the software program Alnuset (see here to download it) to look at (its) affordances. Monaghan described the work (a paper on the topic, there will be a publication in 2013, was available) and then asked some questions. Chiappini distinguishes three layers of affordances: perceived, ergonomic and cultural. Engestroms cycle of expansive learning is used, as I understood it, to use activities as drivers for transformation of ergonomic affordances into cultural affordances. Monaghan then asked some critical questions, under which whether the theory of Engestrom really was necessary, wouldn’t for example Radfords work on gestures be more appropriate? Another comment pondered whether the steps for expansive learning were prescriptive or descriptive. I think the former: as the author has made the software with certain design elements in mind it is pretty obvious that they have a preconceived notion of how student learning should take place. It was pretty hard to discuss these more philosophical issues in detail. I’m not really sure if I even understand the work. Although this could be solely because I haven’t read enough about it, I also feel a bit as if ‘difficult words’ are used to state the obvious. I could only describe what I was thinking off. The article that I took home afterwards gave some more pointers. To get a grasp of this I downloaded the software, that reminded me a bit of the Freudenthal Institute’s ‘Geometrische algebra’ applets, and tried out the software. I liked the idea behind the software. In this example I’ve made three expressions, and I can manipulate x. The other two expressions change with x. Some comments:
I like the way expressions are made and the look and feel, as well as the way dragging changes the expression. Also ‘dividing by zero’ causes expressions to disappear. However, why does x=0 disappear as well when I drag x to 0? (see figure)
I don’t see how the drawback of every tool that allows ‘dragging’, namely just pointless dragging, in this case just to line up the different expressions, is solved. Maybe this isn’t the main goal of the software.
I think that the number line should be used in conjunction with tables and graphs, thus forming a triad expression-table-graphs. The addition of things like an algebraic manipulator and a Cartesian plane seems to indicate that the authors also like more than one representation.
It has far too limited scope for algebra. The 30 day trial is handy here, as in my opinion the software doesn’t do enough to warrant the price.
On Saturday November 17th I visited the second day of the BSRLM conference (British Society for Research into Learning Mathematics). I’ve become a member as it’s ‘the place to be’ for maths education research. This time the conference was in Cambridge, and apparently I was the only one tweeting #bsrlm.
The first session I attended was by Anne Berit Fuglestadt from the university of Agder (soon, homebase of a Dutch researcher I know). She reported about teachers discussing inquiry-based teaching with digital tools.
Fuglestadt describes aspects of using, for example, Cabri and geogebra. A lot of quotes but what can be concluded? #bsrlm
The second half of the session consisted of discussions on instrumental and documentational genesis (The French School, Trouche is an important name). This was fitting, as one PhD student I (co-)supervise is studying instrumentation as underpinning framework for her study.
Ruthven points out the institutional aspect of instrumental/documentational genesis #bsrlm
The second session was an interesting take on use of the Livescribe pen. At first it seemed as if the study, done by Hickman and Monaghan, seemed a bit of a waste of the livescribe pen. Emphasis was put on the audio recording facilities.
Surely the Livescribe isn't used only for audio recording? #bsrlm
Luckily, as I could have expected, they did more with the pen. The pens were used to record student work while ‘thinking aloud’ and these materials (a sort of screencasts of what was written) were used for a combination of stimulated recall and task-based interviews (e.g. Goldin, 1997). Hickman showed some discourse by primary students that was recorded with the pen. It was nice to see student work being ‘constructed’ instead of just having static scans of their work. It also was nice that we could try out the pen ourselves. I did think more can be done with even the older generation of pens. For example, Dragon Naturally Speaking does doe a decent job of transcribing voice, just as long as it is trained to recognize it. It will certainly cut the amount of time you need for transcribing an hours worth of audio.
A joke about students who thought the Livescribe would be able to speak what they've written. Actually, I think, not unrealistic #bsrlm
Another application to use would be Myscript, from the same company that brings a great online equation recognizer. The latest version of the pen also boasts Wifi and Evernote integration, so it looks interesting. It will certainly be worthwhile to check out this for our SKE+ group. A follow-up discussion could be whether these devices will eventually become obsolete if tablet technology with styli, like the Galaxy Note, takes off.
I recently tweeted about the Open Badges project from Mozilla. I did know some things about the project already, as I knew that Hans de Zwart had already written about it. I, however, had not yet read the white paper. To me, it’s clear what the project is all about. What I miss in the white paper is some sort of assessment of the difficulties and/or risks involved.
Open badges website
The tweets that started this dialogue were:
(1) @ it’s just that ‘we’ don’t even know how to conform to open standards regarding h/w, why then learning goals?
(2) @ and as any #gamification course will point out: won’t #openbadges become a goal in itself?
(3) @ and then, if everyone starts to use #openbadges, how then will we prevent everyone using them?
(4) @ and if they are ‘controlled’ who will decide on them, and won’t this create a bureaucratic hazard?
@ So that’s why. Any documents addressing these issues?
Point (1) has a lot to do with all those open standards that are failing because of many reasons. Lets take the recent endeavours for ePub3. I’ve been following the stuff that @fakebaldur has written and tweeted about this, and I can almost understand why Apple did their own iBooks. So this begs the question whether, if we already have difficulty in agreeing on technical standards, something more ‘soft’ like learning goals can be used for an open standard that everyone agrees on, let alone the distribution of them.This brings me to (3) and (4), as addressing (1) maybe implies some sort of control over the development. Mozilla has taken up the glove for now, but how are they gonna lead this. Some models, like the certified user one, could maybe help. Mozilla does seem to think about his (of course) as they talk about Threat Models to prevent badge spamming. User consent then comes into play too. Also, endorsements seem to have a function in this (as stated in the white paper). But the problem here is, as stated with (1), that learning goals are less tangible than ‘just being who you say you are’. Openbadges want to say much more, just like Foursquare says more than just whether someone has checked in. In addition, the rewards for having badges on 4sq for example (and I’m not equating them, it’s just to illustrate a further critical point) do not have a large monetary value. Learning goals could have, and this seems to be presented as an unique selling point, a large value. For this reason, I think it will be very worthwhile for people and instances, and I’m not talking about fraud, to issue badges. I’m not sure how someone, with the aim being to collect badges during his/her lifetime, can cope with the thousands of badges that are to appear. At least, when the framework becomes successful (but if it doesn’t then the worth of the framework is diminished). This is a problem with all initiatives that require enough on-boarding to be worthwhile. As we have seen from other open initiatives this is a paradox: just saying it is worthwhile to use doesn’t make it worthwhile per se. Furthermore, the administrative load could be considerable. And who is going to decide who may endorse and who doesn’t. If I have badge programming 101 what does this mean? Do I get one when I did java? Or one for Python as well? Or are there separate ones. Another paradox: to say something you don’t want badges to be too generic, to have badges for every tiny specialism, even issued by different issuers, some endorsed and some not endorsed, would mean an administration that maybe doesn’t work.
When it comes to gamifying (tweet (2)) learning goals (you want to earn badges, and hopefully be motivated to store them) one point to address is whether people collect badges because they are representations of their knowledge and skills (more intrinsic, because he or she wants to), or because collecting them is ‘cool’ in itself. You don’t want the latter, as it will make collecting badges a goal in itself. This ties in by things I’ve also learned in the Gamification MOOC.
In general, I do not see many writings and comments on these risks, and I think there should be. So, to conclude, has this all been thought through? I’m not saying it couldn’t be worthwhile to pursue this, but I do not see many critical reflections towards the feasibility of it all. I think the case for (or against ;-)) open badges could be better if these issues were addressed.
In the last months I have followed several Massive Open Online Courses. Some I followed because I was interested in the topic (e.g. Machine Learning), some I followed because I was curious how the lecturer would address the topic at hand (e.g. Mathematical Thinking). Let me first admit: I did not or have not yet finished all of them. But because I followed several MOOCs, from varying institutions and on varying topics, I think I can give some kind of opinion. The 4 MOOCs (I’m not counting the ones that I just enrolled to see what content there was) I followed or am following are:
Machine Learning. Running August 20th for 10 weeks. Still on course.
Gamification. Running August 27th to October 8th. Final scores still to be determined but already reached the pass rate of 70/100.
Introduction to Mathematical Thinking. Running September 17th for 7 weeks. Started this, but on a personal level, did not learn that much new stuff. Furthermore, for a ‘feel’ of the method, it resembled the gamification course.
Web Intelligence and Big Data. August 27th for 10 weeks. Did not finish it for reasons that will become clear below.
Organisation and planning
There’s a vast difference in the amount of time that is needed for the various courses. According to the course syllabus, the Machine Learning course should have taken me far less time than, for example, the Mathematical thinking course. Even if I take into account the fact that I already know a lot about mathematics, and not so much on Machine Learning, just the simple fact that there are weekly programming assignments in the former, makes this -in my opinion- a much more time-consuming course. With this comes the number of lectures and the duration of the separate videos. I think it would be good if, if possible, the actual amount of time spent by students was monitored and used for more accurate estimates, maybe even taking into account prior knowledge.
Quality of the materials
Issues like these can cause demotivation
One thing that struck me was the quality of the elements of the courses. Some had engaging speakers, others weren’t as good. Some managed to communicate difficult content, others had trouble doing this. Sometimes visuals added to the lecture, sometimes text was hardly readable. One of the most frustrating experiences I had was feeling as if material that was tested in the quizzes and/or other assignments wasn’t covered in the lectures. The different elements of any course should fit together. If this lack of coherence is accompanied by many mistakes, then demotivation sets in pretty quickly. For me this certainly was the case with the Big Data course. Mind you, I did manage to get reasonable scores, but for me this just wasn’t good enough. Sometimes it even seemed as if it was expected that I had already read up about the topic at hand. I think a MOOC should be a self-contained course, otherwise -although more costly- a MOOC is nothing more than a course at a university with a web-presence. In general, most of the courses do not have a specific text- or course-book; only reading suggestions, that don’t always fit in when it comes to the scope of topics covered, or even the difficulty. I think it would be a good idea if every course would have custom book in a digital format that could be downloaded.
Assessments
Typical checkbox question (here from Machine Learning)
Assessment was done in various ways in the courses. The most common tests were multiple choice quizzes, with some open (numerical) questions in the Machine Learning course. The inline lecture questions were good if an explanation was provided when ‘failing’ three times. If that explanation wasn’t there I had the feeling it was more ‘multiple guess’. The way in which the quizzes for scores were implemented varied considerably. One model is to allow infinite (in practice: 100) attempts for a quiz. I think this corresponds mostly with formative assessment: the tests aren’t there to judge you but are there to let you practice. Quizzes, did however, always count for the final score. So in a world where in the end we do have some sort of high scales test (pass or fail) it could lead to situations whereby 50 attempts yield 100 out of 100 points. Now you can perfectly happy with that as a teacher, after all in the end students knew their answers. I feel that the case of ‘unlimited attempts’ was a bit too lenient. A second model gave students a limited amount of attempts, 5 was used in some. This at least made sure that practicing and re-sitting a test was limited, but students could revise. Revision could not be done by scrutinizing all the questions and answers but only the answers. Because most quizzes had a randomization in their answers (I did not see random questions pooled from a larger amount of questions), yielding a different order of answers and even different answers to the questions, it wasn’t always trivial to improve your score. The questions themselves were a mix of radio button questions, permitting only one answer, and checkbox questions, permitting more than one answer. The latter often were true/false questions but because combined they often made up one question with many answer possibilities, I actually found them harder than de radio button questions. Just crossing away the answers that weren’t realistic wasn’t possible in these cases. Another model was a variation of the limited attempts by imposing a penalty for extra attempts, sometimes from the second but also from the third or fourth attempt. I preferred the ones where a deduction was imposed from the third attempt: it allowed students to revise their work once without penalty (for a second attempt), but it made sure that students would not be able to just click around because then they would get a penalty when they would try for real. Finally, some exams only had one attempt. Given the fact that the questions often were closed and multiple choice I think the quality of the questions hasto be awfully unambiguous. I wasn’t sure this was always the case.
This was the process for peer review in the gamification course
Some courses involved written assignments, like the gamification course. They often were used in a peer review setting. Apart from the fact that some browsers seemed to struggle with the Coursera module for peer assessment, I thought the idea of allowing open written assignments and peer review them was a great idea. Of course, it can be the only way in which you would add these, as the number of students is just too big. What I did find daunting was the peer review itself. Not the comments themselves, I found that most of them were fair (I’m not saying all fair). I did think that the chosen evaluation method, the rubric, was to coarse to fully evaluate the assignments. How should we mark creativity? What if I could only choose between 0, 1, 2 and 3 and I thought 3 was too much and 2 not enough? How do we make sure that all students are treated equal? How do we make sure that grading is done objectively and not compared to the solutions that students themselves had given? I sometimes had the feeling that scores were arbitrary, not resulting in a lower score than deserved but more often in a higher score. I’ve read about one course, which I didn’t follow, where an ‘ideal’ solution was provided by the course-leader, to serve as an example solution. I think that this part of the course has to be fine-tuned to actually give the grades that one deserves.
A variation of the written assignments were the tasks for Mathematical Thinking. They were given in digital format and the goal was to make the assignments and discuss them in a local study group. Although this is great pedagogy I’m wondering whether this isn’t allowing for too much freedom: if I would have the resilience to make assignments on my own, and discuss them, why would we need MOOCs or schools at all? I think it is necessary to have some incentive to actually do this, apart from ‘curiosity’. It also adds to motivation: just the fact that students could just NOT do their work and get away with it, wasn’t all that motivating for me.
A third type of assignment were the programming assignments. Both Big Data and Machine Learning had these. I was extremely impressed by the programming assignments in the latter course. Naturally, programming is more suited for automated grading than open essay questions. You ‘just’ had to evaluate the assignments, often functions you had to write, with arbitrary and random numbers and see if they gave the same results as intended. In the Machine Learning course this is implemented in a wonderful way: you program you work, you test it, you then submit it, and it is graded instantly, returning the score to the system.
At the end of most courses, a score of 70% would earn a ‘statement of completion’.
Intellectual and curiosity level
Programming assignment for Machine Learning
It’s hard to say anything sensible about the intellectual level of the various courses, because it depends so much on the background of the students. Personally I though the Machine Learning course really was a challenge, whereby I would feel a great sense of accomplishment when I managed to train a Neural Net to recognize handwriting. But then my background is mathematics and computer science, so I’m bound to like this. Same holds for Web Data and intelligence, although I’ve already written enough about other factors that came into play. Gamification was an interesting course that really made me think and enabled me to argue why I was for or against a certain point regarding gamification. This was a strong point of that course: it did not shy away from mentioning criticism on the gamification, which made sure that it wasn’t considered ‘the next holy grail’ but a scientific critique of good and bad points. This in itself raised the intellectual level of the course, even though the course material itself was quite simple. As I only followed the Mathematical Thinking course because I was curious about the peer assessment I did the first half but then concluded that, for me, the course did not offer enough. This is not to say that lots of people could do with a bit more mathematical thinking. For every course, and so MOOCs as well, one should really consider the intellectual and curiosity level of the course: is it something you want to know or not?
Responsiveness
Of course MOOCs, in this form, are a new phenomenon. New initiatives will have mistakes in them. Sometimes you’ll just have to start a initiative and work from there. But even then, what I find hard to defend, is the fact that course-leaders aren’t really responsive. Another option is to delegate this to a support community, something that was positive about the Mathematical Thinking course. When students have questions or hints on obvious mistakes they have to be dealt with accordingly, or at least acknowledged. In this sense I was disappointed with the ‘Big Data’ course. In one quiz grading seemed wrong, and when this finally was acknowledged, it brought up a whole new series of mistakes, even with scores being deducted when answers were correct. Again, this doesn’t mean that mistakes are not permitted. ‘Machine Learning’ is in its second run and the forums are full with small mistakes on indexes, symbols that were just misplaced on certain slides. But there weren’t big mistakes (especially in assessments) and mistakes were acknowledged and, if possible, addressed. I would think responsiveness of the course-leader and/or community is another success factor.
Conclusion
I will finish the Machine Learning course and then finish for the moment, as research and teaching gets my priority. I think MOOCs show great potential but just as in real life en education the quality of courses/lessons differ. Therefore, MOOCs are not the holy grail of teaching, and we should be cautious that eager managers think costs can be cut because of MOOCs. MOOCs need, to be good, time and money. And a good teacher. There is nothing new under the sun.
1. Try to set an accurate estimate of the time involved, including the nature of the tasks involved.
2. Make sure that lectures are engaging and the quality of the visuals is up to par.
3. Balance out the course so that all the elements fit together: no surprises.
4. Make sure that there are no big mistakes in lectures, and especially in the assessments.
5. Provide a digital narrative with all, but not more than, the course content (I would suggest this would be freely available).
6. Use a limited amount of attempts in quizzes, and limit the maximum score after a certain amount of attempts.
7. Use a variety of question types in an online quiz.
8. Work out the criteria students have to use when peer grading assignments, for example by providing worked-out examples and fine-tune any rubrics.
9. When not using peer assessment, using written assignments in study groups seem a weak point in the current MOOCs.
10. The mechanism for grading programming assignments is outstanding, and could be used for any programming course.
11. Try to maintain the same level in MOOCs as ‘genuine’ academic courses.
12. Make sure that the course-leaders or the community respond swiftly to mistakes, discussions or inquiries by students.
13. Think up metrics that can be shown with course descriptions, so students can get an impression of the quality of the course.
Of course, most of us will already know Geogebra. The latest incarnation, called GeogebraWeb, is made in HTML5 and is a great next step towards an application -as Geogebra initially is java software- towards software for various platforms, including tablets. In a kickstarter project Geogebra is now asking funds for making an iPad app. I’m wondering why. Sure, I can think of some reasons, including the great demand for it and maybe even some native features can be used more efficiently than in HTML5. But it isn’t open. Also the fact that other tablet users will just have to wait, even though it is jokingly stated that it will eventually become multi-platdorm for other tablets too, seems strange if the philosophy behind geogebra is open-ness. Then why not stick with HTML5!!!??? Or just make sure that both android and ipad apps are released on the same day!!!!???
And there are more questions. One of the novel HTML5 features is a Google Drive connection (screenshots above and below).
This is the file it created
The advantage of providing open tools is that this perhaps could be other online drives as well. How can we be sure that different platforms will communicate with different cloud functions, knowing that, for example, Apple and Google do not always see eye to eye. And that would be a shame. Inter-operability should work for all environments.
NOTE: In an earlier post I already mentioned that storing student tasks online would be beneficial, describing the DME (DWO in Dutch).
After being alerted by a colleague, today I dabbled a bit in Sketchometry. I like it. It can recognize finger gestures, especially useful on tablets, for geometric constructions. There is a calculus function but frankly, this adds nothing to the program. Its strength lies in geometry, and the fact that it works on almost everything, as it is web-based. Furthermore it connects to Dropbox and other cloud-systems. It took a while to get used to the cluttered user interface. Reading this file with available gestures really helped a lot (although there is a mistake, where naturally making a circle should give a circle not a straight line). The number of options and features is not very large.
Midpoint gesture
The quintessential construction is the Euler line. I tried to make this on a Nexus. The screen isn’t big enough, really, for the best experience. Also, the use of my (fat) fingers did not work all that well. Certain gestures were hard to carry out, especially if they involved selecting certain points, like drawing perpendiculars or designating intersections. But even if this was the case, it was great to be able to use gestures, anyway. After around 200 gestures (I had to undo many of them because it recognized the wrong ones) I had something that resembled Euler’s line. I loved the gestures for bisectors and midpoints, with the latter being a one from point to point and a loop in the middle. With quite a few objects the application did seem to slow down considerably, and some icons seemed to disappear.
This could be the case because it could be considered a beta version. What bodes less well for the future is the fact that the most recent post is from Jun 23rd (2012). I hope this does not mean it is the end-product of ‘yet another project’, and now that the project is finished no more updates are given. One of the strengths of for example Geogebra is that it managed to create a large userbase and community working on the software, but also creating content.
Of course, the application would have been even better if it would provide character and formula recognition like in windows 7, Snote by samsung, Inftyreader or visionobjects….. 🙂 But overall it is a great concept!
On twitter I got involved in a discussion on exponents. At first it started with square roots being the same as ‘to the power of 0.5’. The first tweet commented on a blog that stated suprise about the fact that students did not know why the square root of a number was equivalent to ‘to the 0.5th power’. Of course this can be readily proved by using the definition of sum of exponents. I certainly agree with the fact that a lot of students (and teachers?) don’t know why some rules apply. But to me, this is closely related to all the rules that we use. So later on the discussion became more general, and was about when you assume certain properties and when you don’t assume them. For example. proving can be done by using the rule for exponents and so if then . But you could also say that, just like , could be assumed when proven. If you would state: ‘but I want to be proven from the most basic rules and assumptions’ this seems a fair request.
However, then I would say it is not necessary to assume the rule but that is enough. Because let then which is (under this law) . So and so must be 1.
Proofwiki has an excellent list of the (inter-)dependency of exponent laws. I know it perhaps is nitpicking if I say ‘assuming less is better’ but some of the rules and laws we commonly use are not always that trivial. For students this is a nice way to approach it. It even has a link to a great question by a student whether we have to define or prove . Actually I don’t really care whether you prove it or not, but I do think some ‘feel’ for assumptions, axioms, dependencies etc. is useful for everyone. This was the only point I was trying to make.
A special case involves which is indeterminate.
@sndrclsn (who also made this nice picture) tweeted about his great movie bij James Tanton on “zero to the zero”-th power.
It sparked many more musing, like plotting in Wolfram and in Google. But there are other views, like this one stating that and also the Math Forum has some interesting quotes.
 t. She described the evolution of teacher tools for student progress within the system. She showed an, in my opinion, very interesting visualization of student progress, essentially a logfile. I recognized a lot of the difficulties with analyzing logfiles of student progress in my PhD. Good to see they’re working on a web-based version as well. The fourth presentation showed Maths-Whizz work. I was impressed by their dashboard and visualization. Less impressed by the actual maths content I saw in the sample. For example, why do I get 0 points if my third step in the equation in the figure?
t. She described the evolution of teacher tools for student progress within the system. She showed an, in my opinion, very interesting visualization of student progress, essentially a logfile. I recognized a lot of the difficulties with analyzing logfiles of student progress in my PhD. Good to see they’re working on a web-based version as well. The fourth presentation showed Maths-Whizz work. I was impressed by their dashboard and visualization. Less impressed by the actual maths content I saw in the sample. For example, why do I get 0 points if my third step in the equation in the figure?













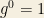 can be done by using the rule for exponents
can be done by using the rule for exponents  and so if
and so if 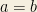 then
then  is enough. Because let
is enough. Because let  then
then  which is (under this law)
which is (under this law) 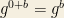 . So
. So  and so
and so  must be 1.
must be 1.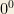 which is indeterminate.
which is indeterminate. in
in  and also the
and also the