Update: added a little bit on the ‘leadership’ aspect and made wording more precise.
I covered the costs of routes into teaching before. Two reports have been released, one by the Institute for Fiscal Studies (funded by the Nuffield Foundation) and one by Teach First and Education Datalab. I must say, it doesn’t seem a coincidence Teach First commissioned another report and releases it exactly on the day the IFS report is published. I can understand why because the report(s) together give the impression that: TF is expensive, has low retention (saying it is higher in year 2 is strange as the Teach First programme lasts two years), teacher do not stay on in challenging schools BUT the ones who do stay end up in leadership functions and higher salaries. Both reports are interesting reading and I applaud the transparency behind them. What was even more interesting though was the social media and press flurry around them. In this post, I’d thought it would be good to tabulate the numerous tweets and comment on several first-hand press releases.
First a blog by the Education Datalab, which led both studies. This first describes the worse retention but then makes a case for the good aspects of Teach First. Although I think these good aspects should not be undervalued I did have some questions about some of the points highlighted, including some errors.
The error concerns the reporting of the benefits. Data was not from headteachers, as stated in the blog but secondary subject leaders (see my older blog on the report in draws from). In addition, we could also present the ‘secondary ITT coordinators’ which shows higher or at least comparable perceptions of benefit, except for salaried SD.
I also wonder where the ‘much more likely to continue to work in schools in challenging circumstances’ comes from, as the report seems to say that it may be the case after 3 years but that this reversed after 5 years. There is an additional graph (Figure 4) based on Free School Meals but that also shows a shift from higher percentages of FSM towards lower percentages FSM. I think there should be genuine concerns about this, if the idea is that the disadvantaged’ are helped. In any case, the migratory patterns of trainees need further scrutiny.
Finally, the ‘seven times’ is based on data on different cohorts. The text talks about different numbers in the table, I would say it’s 4 against 25, which of course is not seven ( a minor point). The text does mention that other routes are one year less on the job market, but I agree that it is hard to account for that.
However, what I do miss is some critical reflection on the nature of these positions. Sure, there are more in leadership positions, but are they within their original MAT? Schools within MATs? Newly founded free schools? Given the objective regarding ‘disadvantaged students’ it seems there needs to be a bit more analysis before one could say that objective is reached most effectively through ‘leadership’. It certainly isn’t through teaching as the IFS report already established that less were teaching. The establishment of charities seems a less convincing cause of reduced inequality. Given the difficulty to get school leaders I can see a place for this, by the way, but we should ask whether the much larger investment of public funds is worth the developed leadership AND whether it really ends up helping the disadvantaged. I, for one, have always said that not a lot of pressure comes out of Teach First to argue for systemic actions to address poverty and inequality. Also, the argument that TF-ers would otherwise would not have gone into education could be cynically parried by “and 60-70% doesn’t because they go to other pastures”. Is the return of investment really worth it, just looking at the expense? (And not an, in my view, emotive argument that they are such fine teachers).
Of course Teach First also had their own series of press releases. Understandably they liked to stress the ‘leadership’ aspect more than cost and retention. But they also had a post asking for more investment in research into teaching training routes. I thought the press release was a bit too defensive, to be honest. It starts off with basically saying that the comparison had not been fair, in my view surprising because previously -when the IFS had used an in my view strange way to calculate Teach First’s larger benefits– there had been no complaints about that. Towards the end it actually is repeated.
It is important to first say that I agree that more transparency of these costs and benefits is needed over the board. Of course part of the transparency is supplied by the report. Nevertheless, there still might be information that is unknown (for example, upfront I personally was wondering what part of the cost actually was covered by third party donations) and we need to realise that. The text then goes on to emphasise the ‘leadership benefits’ and again suggest it had ‘not been a fair comparison’ without actually explaining why. One aspect, it seems, concerns long term teacher quality. Although I agree with that statement, it seems a bit strange to first explain what the study did *not* study nor was asked to study. I have no doubt that Teach First provides a good quality provision, yet it needs to be off-set against the cost, just like any provision. I do know that ‘good’ and ‘outstanding’ are relatively unhelpful notions to describe, as most provisions *must* have level 3 and 4 trainees to survive (as far as I know).
Finally, then, the findings of the IFS report are addressed. I think saying the programme’ is ‘three years’ (by including recruitment) is a bit strange. Initially there were some thoughts that previous calculations did not take into account the fact that an TF or SD trainee would immediately teach in the first year, but on page 19 it is clear this has been accounted for.
Of course it is true that TF trainees do more than just PGCE and QTS, namely ‘leadership’, and that within the teachers that stay do so effectively, but I’m not sure if that is the core aim of such a programme.
The second point regarding recruitment costs seems fair, but needs to be said that TF asks schools for a recruitment fee as well. SD fees were also taken into but are much lower. I don’t think HEI fees were included but would expect that they would be lower as well, as universities can make use of extensive PR departments any way. Overall, though this might lower the total cost (see later on).
Another point made concerned the donations.
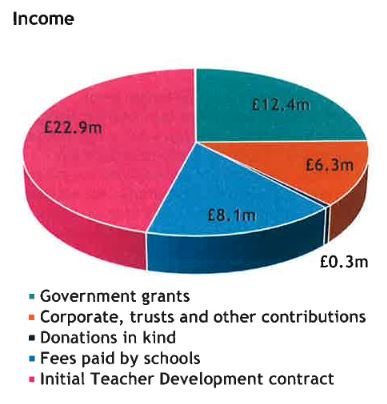
It is correct to say this is ‘not cost for the taxpayer’ of course, although it does make sense to look at all costs to evaluate the ‘value for money’. After all, if we would state that TF produces better outcomes then this might be caused by more money being pumped into their trainees.Looking again at the net funding:
It is sensible to ask what of that *is* public and what is not. Looking at those direct grants from the NCTL we can look at the year reports and conclude that Teach First received around £ 40 million in 2014-2015 to cater for 1685 trainees which is around 24k per trainee (actually, the 13-14 data was £ 34 million against 1426, about similar).
If we now also take into the direct costs to school, the upfront recruitment fee of 4k then it seems that the ‘voluntary contribution per trainee’ is rather low. Of course what is difficult is to unpick what money is actually used internally for what, so let’s also look at the total income of Teach First for 13-14 and 14-15 respectively (this is the 2014-2015 year report for Teach First):


Simply dividing the total ‘Corporate, trusts and other contributions’ by the total number of new trainees per year yields an amount of £4400-£4800. Of course not all of that might go towards training. According to the online appendices to the first report voluntary contributions for Teach First are £ 1200. Off-setting all of this against aforementioned costs they make a difference but even if we would subtract all the donations and recruitment fees, the costs stay high. I would even say it’s a bit disingenuous to focus attention on these cost types, as it suggests the work is poor (although readily cited in places where the outcome seems more favourable). The cost must be discussed, not downplayed. The last point of the Teach First press release concerns the bursaries. This, of course, is a valid point from the viewpoint of the student. I think the absurdly high costs of the bursary programmes certainly need to be taken into account. But these bursaries are not ‘cost of the programme’ rather a stimulus for individuals. I think that money can be better spent to attract teachers.
The press release finishes with:

It is interesting that Teach First uses ‘four years’ because as mentioned previously the IFS reports seems to indicate that it has changed after 5 years. The last point is a variation of incorrect reporting mentioned previously, namely that schools mentioned the benefit; they didn’t they were subject specialist and ITT coordinators in the schools gave a different picture. In an older blog I already criticised the emphasis on ‘value of benefit’ in the 2014 report.
After reading all these sources I would say:
- Teach First is much more expensive than other routes, even after taking into account school fees, recruitment, first year teaching and donations;
- Teach First has a much stronger leadership focus than other routes;
- Retention in Teach First is worse than other routes;
- There is a shift from TFers working more in ‘requiring improvement’ and ‘inadequate’ schools towards ‘good’ and ‘outstanding’ from year 3 to year 5;
- The ‘benefit’ from the 2014 IFS report is misreported;
I think Teach First is a valuable route into teaching with passionate leadership and alumni ambassadors (important: criticising cost is not criticising individuals), but it is important to evaluate the overall cost of such a programme (per trainee). Certainly in a time where both provider-led teacher training and school direct programmes have to train with vastly smaller amounts of money (for example 9k for HEI but they normally pay part of this to schools for mentoring), it is realistic to look at ‘added value’ for education. Maybe that is ‘leadership’. Maybe that’s ‘helping the disadvantaged’. But even if we think those need to be addressed it doesn’t help if retention is low and teachers end up in better schools. Rather than say ‘not a fair comparison’ it would be best to address these aspects head on.

 Sometimes I just get carried away a bit. I managed to get an early copy of Daisy Christodoulou’s new book on assessment called Making Good Progress. I read it, and I made notes. It seems a bit of a shame to do nothing with them, so I decided to publish them as blogs (6 of them as it was about 6000 words). They are only mildly annotated. I think they are fair and balanced, but you will only think so if you aren’t expecting an incredulous ‘oh, it’s the most important book ever’ or ‘it is absolutely useless’. I’ve encountered both in Twitter discussions.
Sometimes I just get carried away a bit. I managed to get an early copy of Daisy Christodoulou’s new book on assessment called Making Good Progress. I read it, and I made notes. It seems a bit of a shame to do nothing with them, so I decided to publish them as blogs (6 of them as it was about 6000 words). They are only mildly annotated. I think they are fair and balanced, but you will only think so if you aren’t expecting an incredulous ‘oh, it’s the most important book ever’ or ‘it is absolutely useless’. I’ve encountered both in Twitter discussions.