In ReproLab I try to reproduce or replicate findings from research articles.
This reproduction is for:
Kestin, G., Miller, K., Klales, A., Milbourne, T., & Ponti, G. (2025). AI tutoring outperforms in-class active learning: An RCT introducing a novel research-based design in an authentic educational setting. Scientific Reports, 15(1), 17458. https://doi.org/10.1038/s41598-025-97652-6
This is quite a viral AI article which is often used for large claims about AI, especially to argue that AI tutors teach physics twice as well as Harvard professors.
Of course, currently, everyone is clambering to get their AI studies out, because they are dated within a week. It was surprising to see that the article was received on 25 March 2025 and accepted 13 days later on 7 April 2025. Good things about the study were:
- Strong experimental design, compared with an active learning condition rather than ‘lecturing’.
- Information about the AI design.
- Sizable effect sizes, engagement and motivation higher in the AI condition (can be novelty effect) but enjoyment and growth mindset similar (so not superficial), and
- Data made available (see below for the reproduction).
However, we must highlight limitations as well if this study used as blueprint for education systems as a whole:
- The study is one single institution (with presumably high entry tariff), a single course and for only two weeks.
- Short-term outcomes.
- The AI tutor took a long time to design, so this can’t be compared with out-of-the-box AIs.
- Ceiling effects…but that could also mean that learning effect underestimated.
- Medium versus pedagogy: the AI condition was asynchronous, self-paced, and at home; the in-class condition was synchronous and in-person.
- Novelty effect (see positives as well).
I’m sure there are other points, but you’d want more of these studies, and it therefore is slightly annoying that the Tutor and TeachGPT not available, although prompts are made available. LLMs are just to unpredictable to really rely on this, a general challenge in reproducing findings.
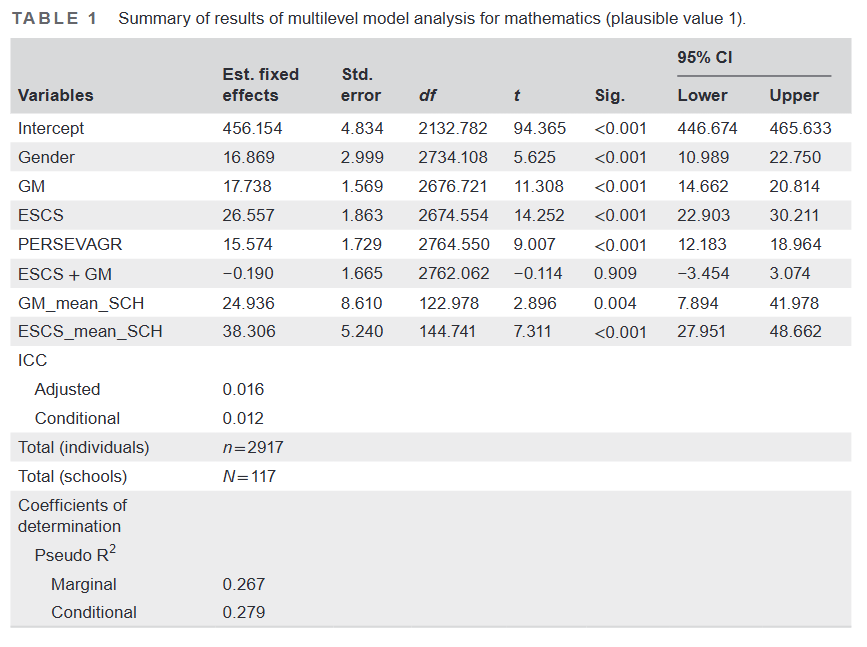
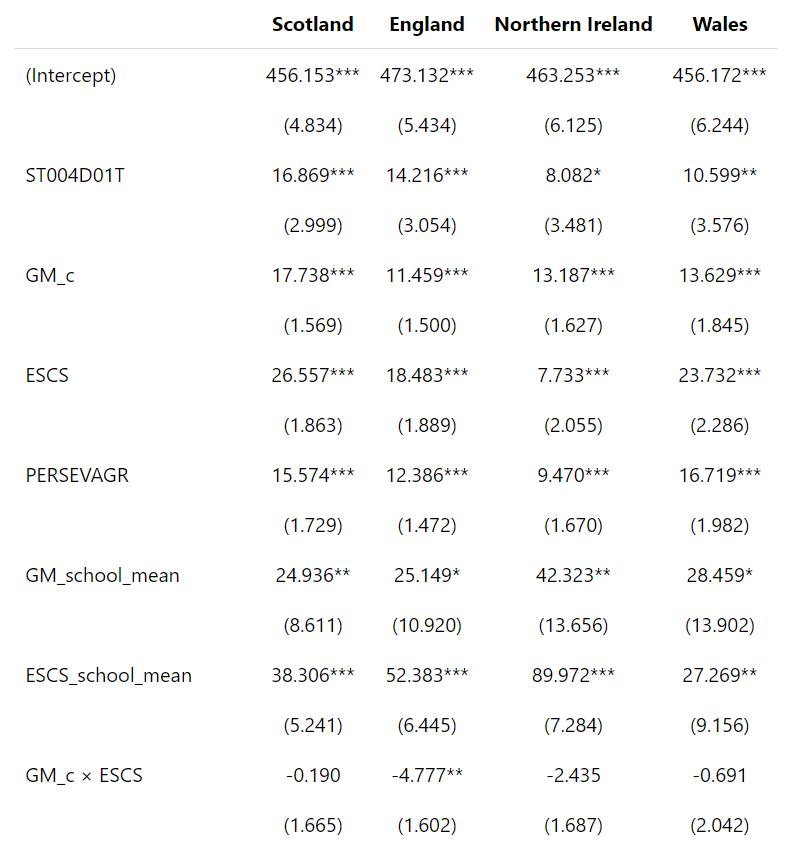
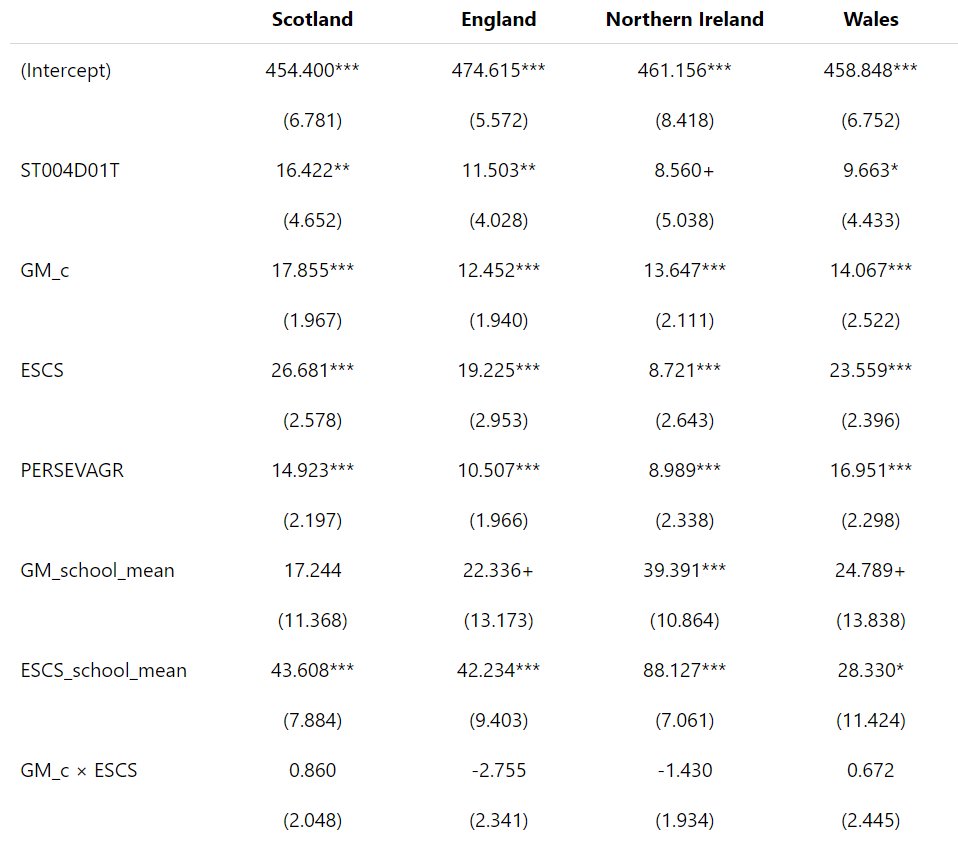
What is available is the data though, and I could reproduce the results. Figures produced with R below (they look different but essentially the same):
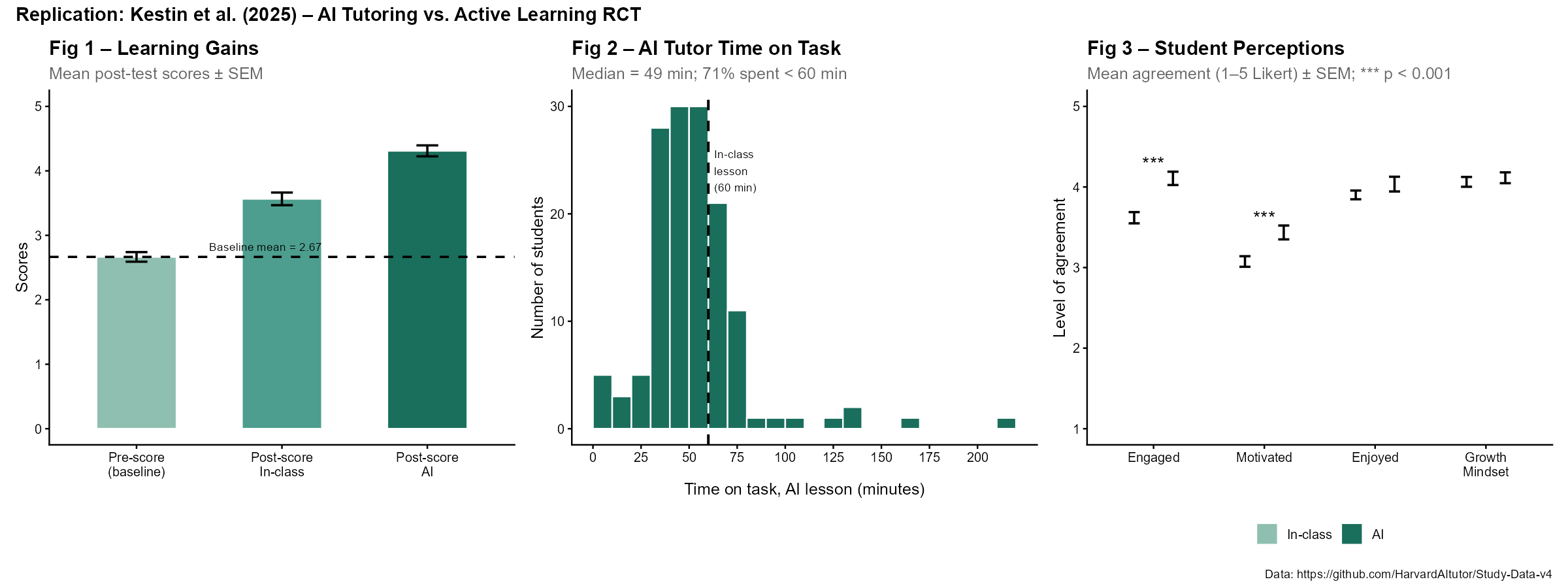
I used the link to the data in the article.
The R script is here.